
Active Repository is good & Awesomely Usable

This is Part One of Practical Software Architecture series.
A blog posts series I’m planning to post unscheduled whenever a practical need arise in a real-world use case. It’s also an evolving and incremental experience, so some point of views may be changed overtime. While the following topic may be controversial, and I’m not that person who enjoys such argumentative discussions, I see it’s a must to declare the why behind our newly released open-source package “Rinvex Repository” and my opinions why I built it that way.
Glossary
Here we define some common definitions and terms used in the following context that serves the purpose of this writing.
Domain Model: Active Record Models / Data Layer / Business Logic
Client Objects: Application Layer / Service Layer / Controllers
Data Source: Data Store (whatever database or web service)
Entity: Another abstract name used interchangeably with domain model. Maybe called also business entity.
Aimed Behavior
- Client objects interact with repositories, and only repositories.
- Domain model is the main interface that interacts with data source.
- Repositories may store data access logic, query or persist domain model, and utilize ORM & query objects.
Introduction
Design patterns do not depend on specific technology, framework or programming language. Once you understand the chosen design pattern, it doesn’t matter what framework or programming language you are going to use & you can implement it in whatever technology you want. With that in mind, let’s start with Martin fowler‘s definition of the Repository Pattern:
A Repository mediates between the domain and data mapping layers, acting like an in-memory domain object collection. Client objects construct query specifications declaratively and submit them to Repository for satisfaction. Objects can be added to and removed from the Repository, as they can from a simple collection of objects, and the mapping code encapsulated by the Repository will carry out the appropriate operations behind the scenes.
Conceptually, a Repository encapsulates the set of objects persisted in a data store and the operations performed over them, providing a more object-oriented view of the persistence layer. Repository also supports the objective of achieving a clean separation and one-way dependency between the domain and data mapping layers.
And his definition of Active Record:
An object that wraps a row in a database table or view, encapsulates the database access, and adds domain logic on that data.
An object carries both data and behavior. Much of this data is persistent and needs to be stored in a database. Active Record uses the most obvious approach, putting data access logic in the domain object. This way all people know how to read and write their data to and from the database.
Well, while these definitions clear & concise; we will use a hybrid of both that’s not strictly adheres to the original definitions. And the fundamental idea or the primary goal behind that is to create a bridge or link between domain (active record models) and client objects (application layer / controllers). In other words, to decouple the hard dependencies of domain models from the client objects, centralize caching strategy, easily swap data store implementations.
Precaution
Whether you think the following implementation or what could be called metaphorically “Active Repository” (due to the hybrid between active record & repository pattern), whether you think it’s anti-pattern, or flawed implementation, I won’t argue with you. The whole “Design Patterns” topic is controversial in the PHP world! Honestly I respect every opinion about this, and without any judgement they’re all correct. Yes, all of them :) Not every design pattern is suitable for every use case.
Regardless of what you may say, I’m a Laravel enthusiastic guy, with opinionated way in doing things. Without arguing about the high level philosophical and pragmatic definitions, I’m saying that’s simply my way in abstracting data-layer and caching results, that could save you some work and time; most of my career involves building enterprise solutions for small and medium business, so it’s apparently the mid-class, mid-size scale of apps, and that’s the category I’m building all my thoughts about, and guess what? It’s working very well. Those in favor can use it, others who are neutral can code to an interface, and those who don’t like the whole idea, it’s OK, I accept constructive criticism; but keep in mind that getting things done in a clean and organized way, is our ultimate goal, not just sticking to SRP & SOLID principles for every use case.
So, this is my way in using the hybrid of Active Record & Repository Pattern to work for me well, and satisfies required objectives.
The Baseline
Design patterns are molds, some like to strictly adhere to them on the basis of principal and well-written code. Strictly adhering to a pattern probably won’t give you bad code, but it could take more time and cause you to write much more code.
Design patterns are flexible, adjust them to suit your needs. Bend them too much and they break though. I realize design patterns are guidelines, not rules set in stone to be implemented whenever possible. Know what you need and pick a design pattern closest to that.
Context
In many applications, the client objects accesses data from domain models which represents data sources such as databases, or web services. Directly accessing the data can result in the following:
- Duplicated code.
- Weak typing of the domain model.
- A higher potential for programming errors.
- Difficulty in centralizing data-related policies such as caching.
- An inability to easily test the client objects in isolation from external dependencies.
Objectives
Use the Repository pattern to achieve one or more of the following objectives:
- Apply centrally managed, consistent access rules and logic.
- Implement and centralize a caching strategy for the domain model.
- Improve the code’s maintainability and readability by separating client objects from domain models.
- Maximize the amount of code that can be tested with automation and to isolate both the client object and the domain model to support unit testing.
- Associate a behavior with the related data. For example, calculate fields or enforce complex relationships or business rules between the data elements within an entity.
Solution
The client object should be agnostic to the type of data that comprises the data source layer represented by the domain model. For example, the data source layer can be a database, or a web service. A repository comes in to the play with methods to access the domain model while the client object uses this repository to interact with the domain model instead of directly using it by itself.
The repository in our implementation mediates between the client object and the domain model of the application. It queries the data source for the data (mainly through the domain model), and persists changes in the domain model to the data source. A repository separates the client objects from the interactions with the underlying data source. The separation between the application and data layers has many benefits. Some of them are:
- Reduces code duplication.
- Swapping out implementations became easy.
- A lower chance for making programming errors.
- Client objects and domain models can be tested separately.
- Centralization of the data access logic makes code easier to maintain.
- It provides a flexible architecture that can be adapted as the overall design of the application evolves.
There are two ways that the repository can query data source. It can submit a query object to the data source or it can utilize ORM methods that specify the business criteria. In the former case, the repository forms the query on the client’s behalf. The repository returns a matching set of entities that satisfy the query. The following diagram shows the interactions of the repository with the client and the data model.
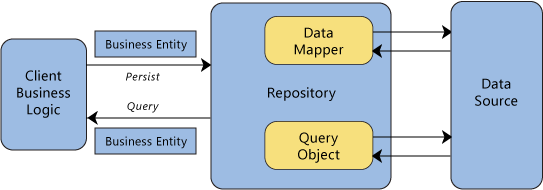
The client object submits new or changed entities to the repository for persistence. Repositories are bridges between data and operations that are in different domains. A repository issues the appropriate queries to the data source through the domain model, and then it maps the result sets to the externally exposed client objects. Repositories often use the ORM to translate between representations. Repositories remove dependencies that the calling clients have on specific technologies. For example, if a client calls a catalog repository to retrieve some product data, it only needs to use the catalog repository interface. For example, the client does not need to know if the product information is retrieved with SQL queries to a database or Hypertext Transfer Protocol (HTTP) RESTful request to a web service. Isolating these types of dependencies provides flexibility to evolve implementations. Communication between the client object and the domain model is done through interfaces.
To put it simply, the repository is a kind of container where data access logic is stored. It hides the details of data access logic from client objects. In other words, we allow client objects to access the domain model without having knowledge of underlying data access architecture.
It’s all about interfaces
Repository pattern is all about interfaces. An interface acts like a contract which specify what a concrete class must implement. Let’s think a little bit. If we have two domain models Student and School, what are common set of operations that can be applied to these two domain models? In most situations we want to have the following operations:
- Find all entities.
- Paginate all entities.
- Find an entity by its primary key.
- Find an entity by one of it’s attributes.
- Find all entities matching where conditions.
- Find all entities matching whereIn conditions.
- Find all entities matching whereNotIn conditions.
- Create a new entity with the given attributes.
- Find the first entity matching the given attributes or create it.
- Update an entity with the given attributes.
- Delete an entity with the given id.
Can you see now how much duplicated code would we have if we implement this for each domain model? Sure, for small projects it’s not a big problem, but for large scale applications it’s a bad news.
Now when we have defined common operations, we can create an interface:
interface UsesRepository
{
public function find($id, $columns = ['*'], $with = []);
public function findBy($attribute, $value, $columns = ['*'], $with = []);
public function findAll($columns = ['*'], $with = []);
public function paginate($perPage = null, $columns = ['*'], $pageName = 'page', $page = null);
public function findWhere(array $where, $columns = ['*'], $with = []);
public function findWhereIn($attribute, array $values, $columns = ['*'], $with = []);
public function findWhereNotIn($attribute, array $values, $columns = ['*'], $with = []);
public function firstOrCreate(array $attributes);
public function update($id, array $attributes = []);
public function delete($id);
}
While this is true that an interface is like a contract but also there are other things an interface does. It is being used an abstraction layer between the client object and the domain model. In other words an interface hides the details from the client objects when the interface is used to type hint the data type as a dependency of the client object.
Implementation Details
For the implementation details, instead of going down very technical and describe how this whole implementation works, I’d rather keep this article as the why and delegate the how to the readme file of “Rinvex Repository” package over github.
Considerations
This Active Repository implementation increases the level of abstraction in your code, which may make the code more difficult to understand for developers who are unfamiliar with the pattern. Although implementing the pattern reduces the amount of redundant code, it generally increases the number of classes that must be maintained.
So, finally, it’s not important that you must follow the rules and principles in every project but it’s a good practice, if you didn’t follow it, it will still work and it’s not a sin, you should decide what to do and how to do it. Keep in mind that following some rules blindly doesn’t makes any sense, it may create problems if applied inappropriately, so why not use your sense without blindly following some pro, some one said it’s good practice so I’ll do this, if this is the case then it’s not good at all. Always ask why, and look for the best how that fits your needs, there’s always alternatives. And as usual, there’s always multiple right ways, and not every practice or rules are suitable for every use case.
A Room For Enhancement
Since this is an evolving implementation that may change accordingly depending on real-world use cases, it’s worth mentioning that the caching layer could be decoupled more, may be I’ll rethink the whole caching layer in a Decorator Pattern way. I also admit that this implementation is tightly coupled to Laravel Eloquent in some way, and has some leaking implementation details, specifically in the context of filtration and using scopes, this likely to be changed and rethought in a Criteria Pattern way in the future.
References
I’d recommend you make your own decision, and to do so don’t just approve what I or anyone else says, read every possible opinion, know your requirements, and pickup the best solution that fits your needs. Do whatever you want ;) Here’s some helpful references that inspired me on that topic:
- Active Record Basics by RailsGuides.
- Repository Pattern Purpose by domnikl.
- Repository pattern, done right by jgauffin.
- MSDN definition of the Repository Pattern.
- Martin fowler’s definition of the Active Record.
- The Repository Design Pattern by Patkos Csaba.
- Martin fowler’s definition of the Repository Pattern.
- Laravel – Using Repository Pattern by Sheikh Heera.
- Using Repository Pattern in Laravel 5 by Mirza Pasic.
- Active Repository is an anti-pattern by Adam Wathan.
- What are the benefits of using Repositories? by Philip Brown.
- DDD: Repository Implementation Patterns by Jimmy Bogard.
- A debate on Reddit about my way of repository implementation.
- The Repository PatternBasics and clarification by Shawn McCool.